News
- 2025/05/21: We collaborated with Mistral AI and released Devstral Small that achieves 46.8% on SWE-Bench Verified!
- 2025/03/31: We released an open model OpenHands LM 32B v0.1 that achieves 37.1% on SWE-Bench Verified (blog, model).
Quickstart: Running OpenHands with a Local LLM using LM Studio
This guide explains how to serve a local Devstral LLM using LM Studio and have OpenHands connect to it. We recommend:- LM Studio as the local model server, which handles metadata downloads automatically and offers a simple, user-friendly interface for configuration.
- Devstral Small 2505 as the LLM for software development, trained on real GitHub issues and optimized for agent-style workflows like OpenHands.
Hardware Requirements
Running Devstral requires a recent GPU with at least 16GB of VRAM, or a Mac with Apple Silicon (M1, M2, etc.) with at least 32GB of RAM.1. Install LM Studio
Download and install the LM Studio desktop app from lmstudio.ai.2. Download Devstral Small
- Make sure to set the User Interface Complexity Level to “Power User”, by clicking on the appropriate label at the bottom of the window.
- Click the “Discover” button (Magnifying Glass icon) on the left navigation bar to open the Models download page.
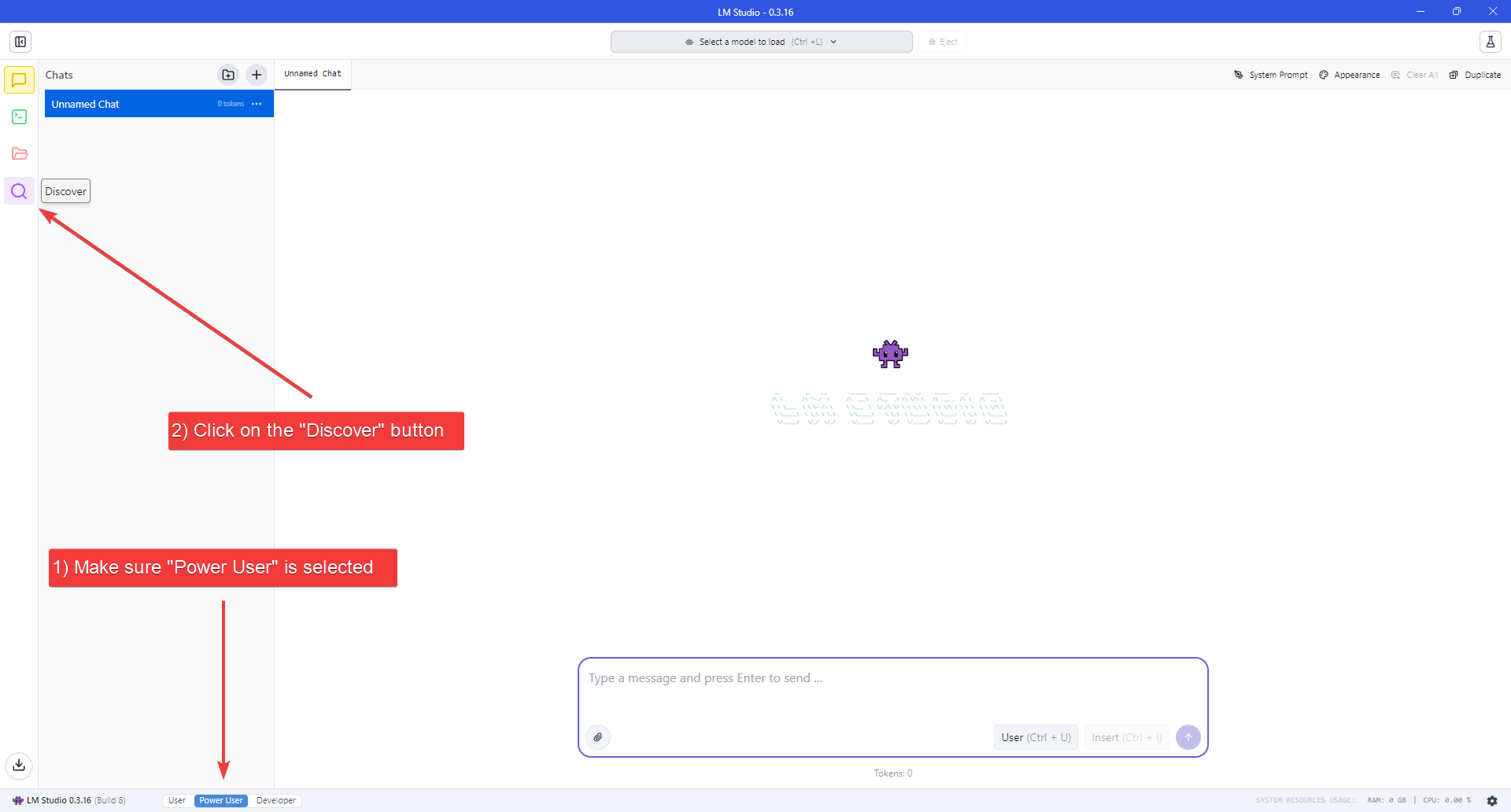
- Search for the “Devstral Small 2505” model, confirm it’s the official Mistral AI (mistralai) model, then proceed to download.
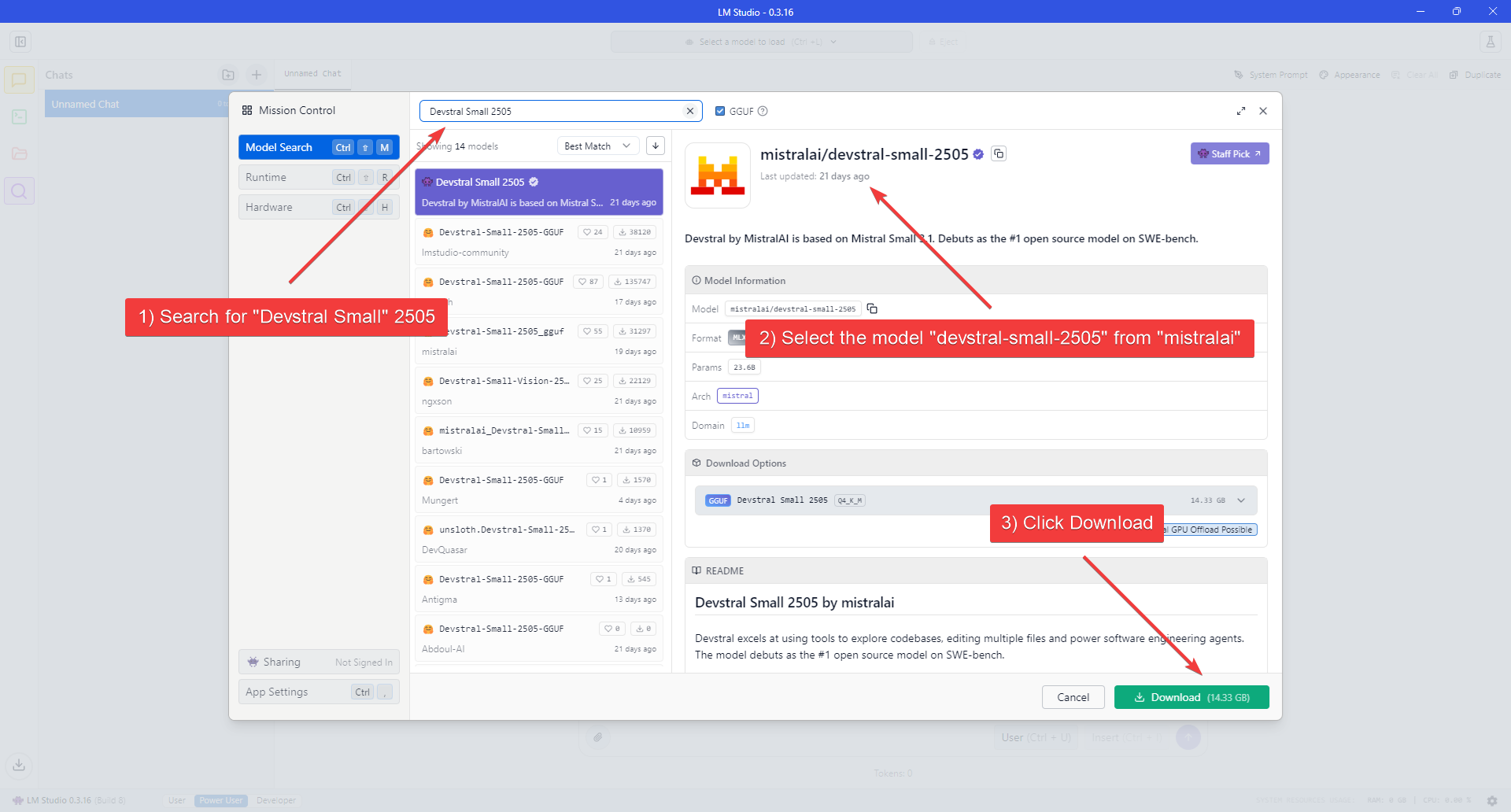
- Wait for the download to finish.
3. Load the Model
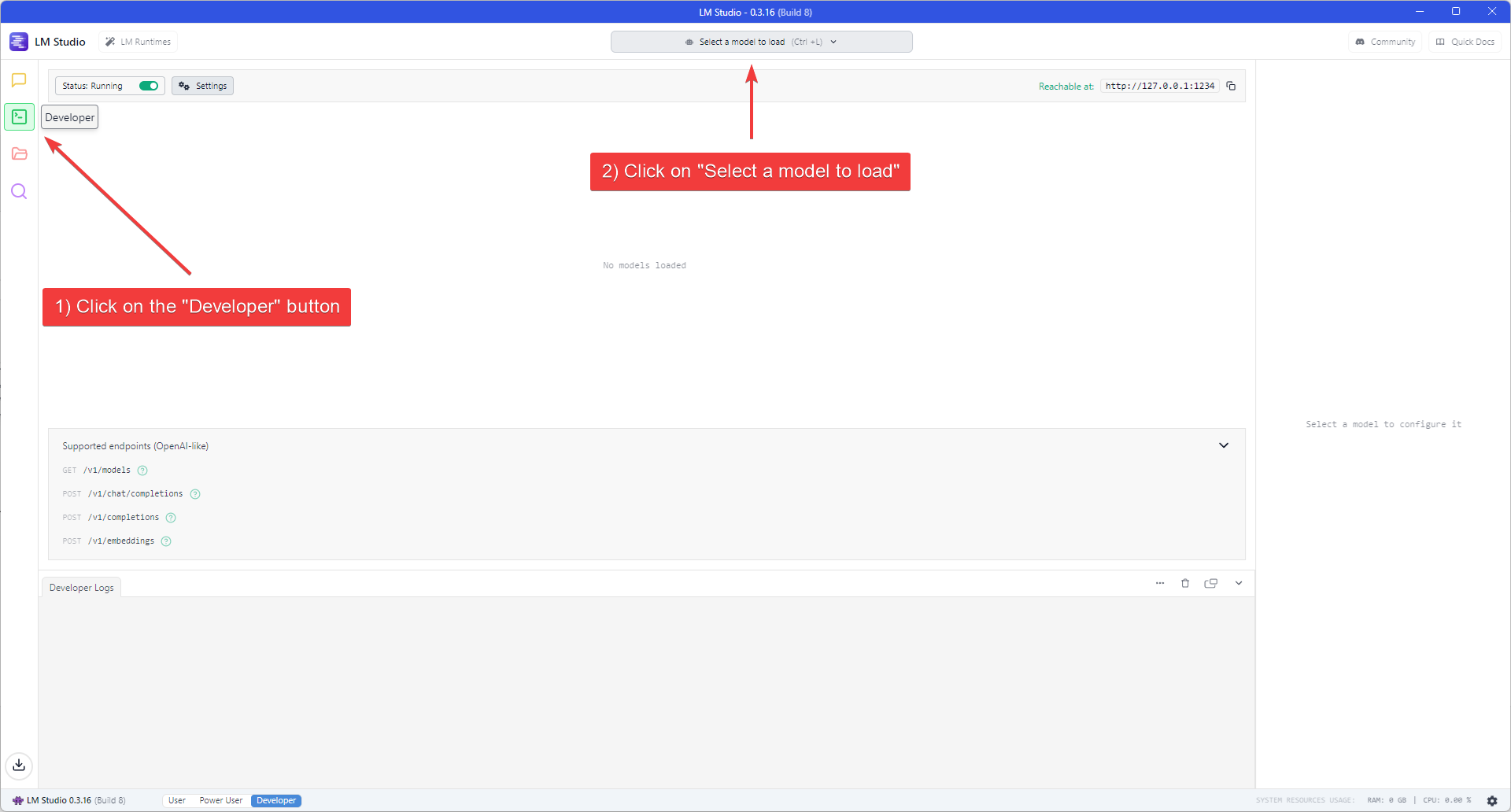
- Click the “Developer” button (Console icon) on the left navigation bar to open the Developer Console.
- Click the “Select a model to load” dropdown at the top of the application window.
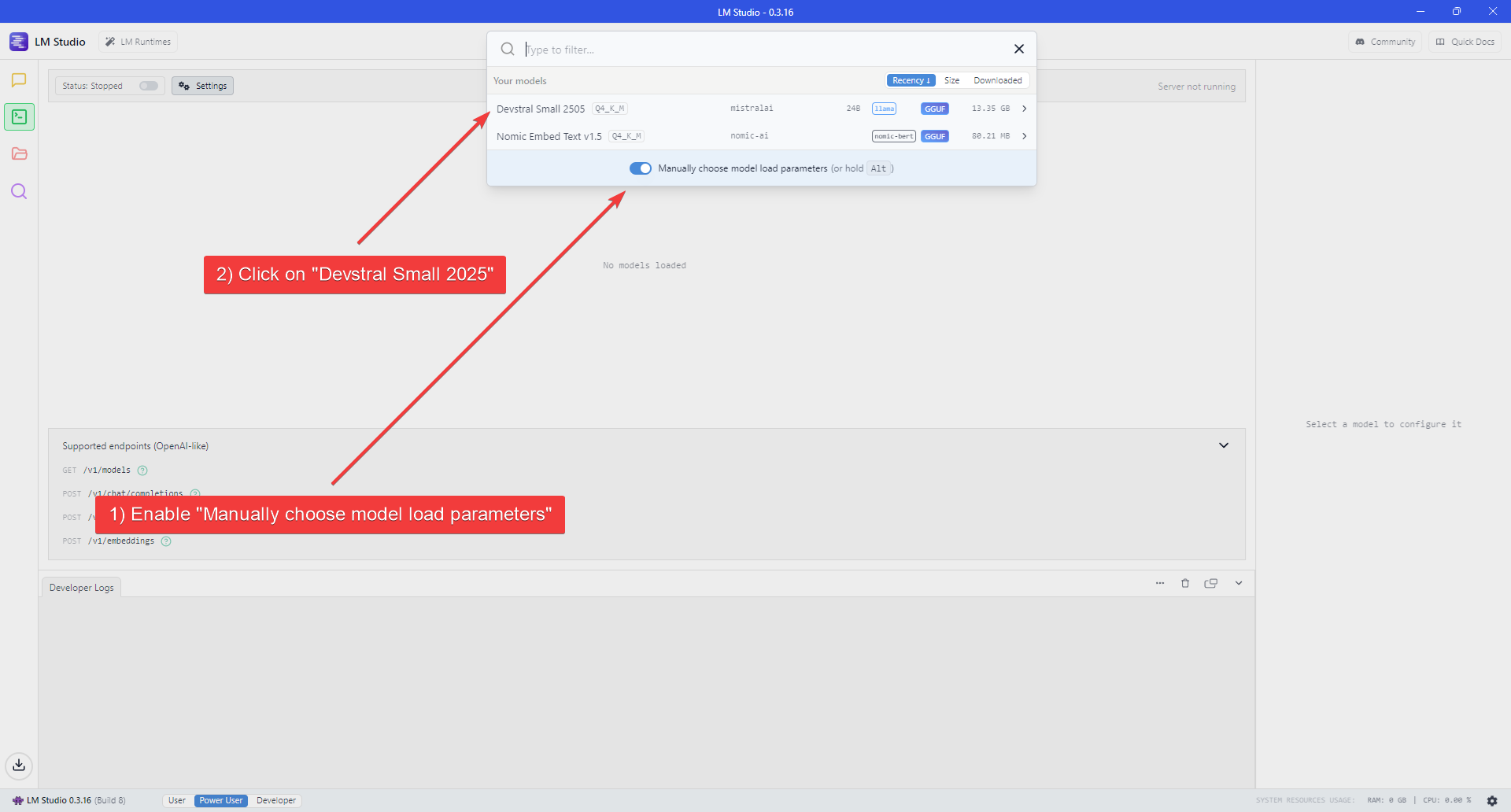
- Enable the “Manually choose model load parameters” switch.
- Select ‘Devstral Small 2505’ from the model list.
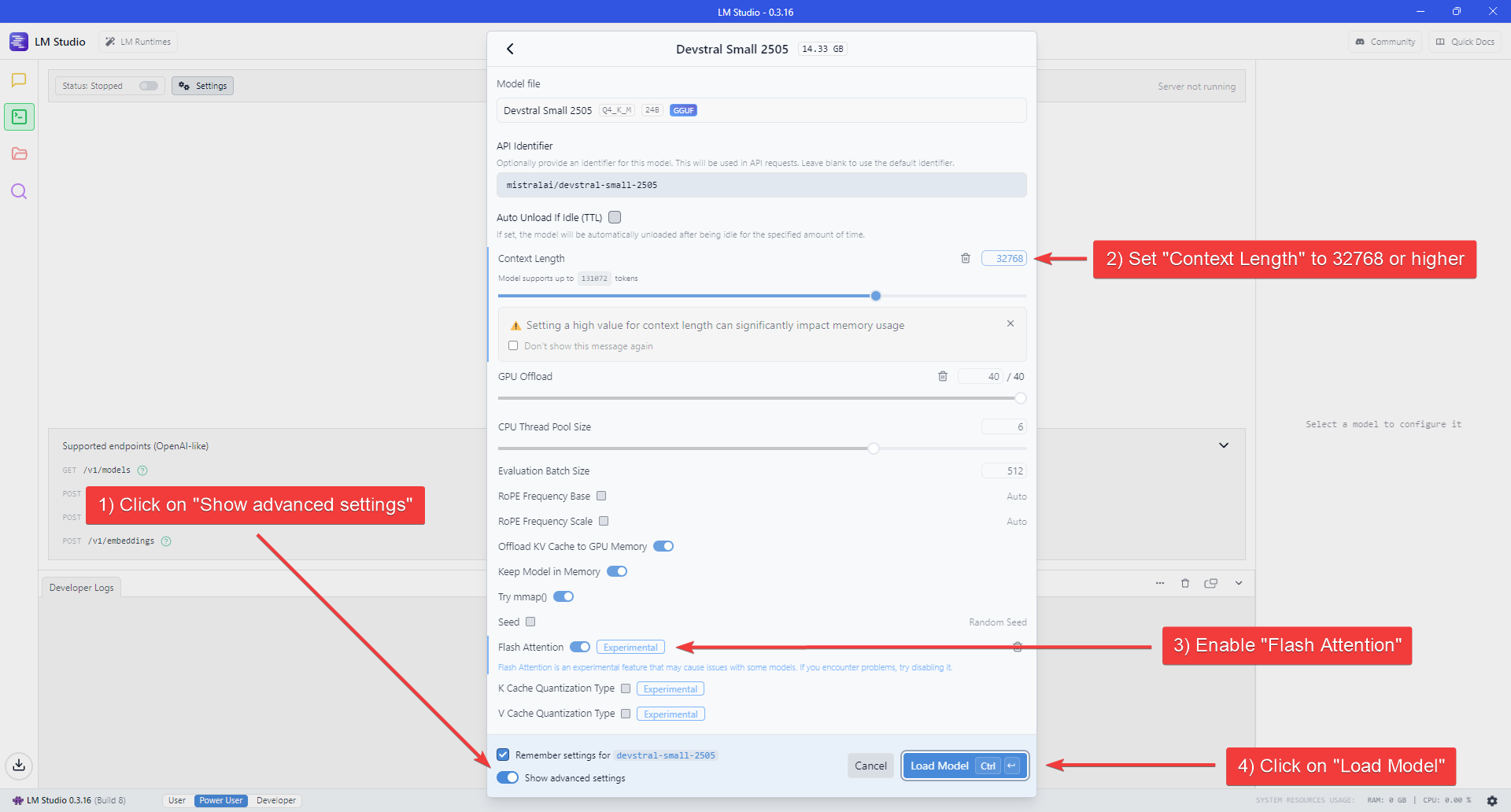
- Enable the “Show advanced settings” switch at the bottom of the Model settings flyout to show all the available settings.
- Set “Context Length” to at least 32768 and enable Flash Attention.
- Click “Load Model” to start loading the model.
4. Start the LLM server
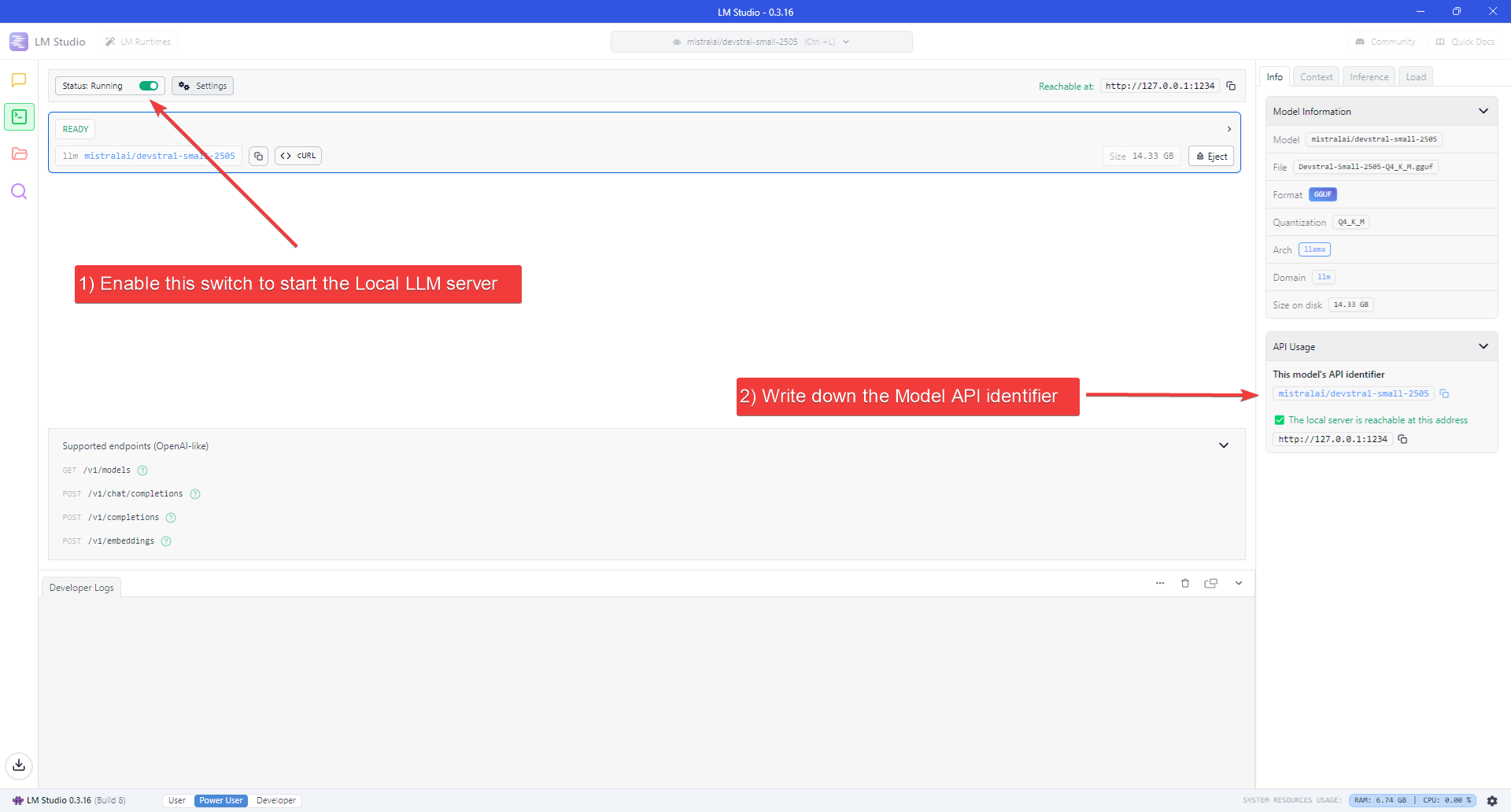
- Enable the switch next to “Status” at the top-left of the Window.
- Take note of the Model API Identifier shown on the sidebar on the right.
5. Start OpenHands
- Check the installation guide and ensure all prerequisites are met before running OpenHands, then run:
- Wait until the server is running (see log below):
- Visit
http://localhost:3000in your browser.
6. Configure OpenHands to use the LLM server
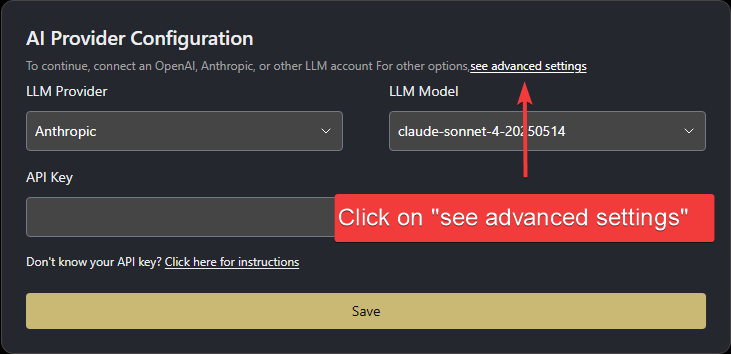
Once you open OpenHands in your browser, you’ll need to configure it to use the local LLM server you just started. When started for the first time, OpenHands will prompt you to set up the LLM provider.- Click “see advanced settings” to open the LLM Settings page.
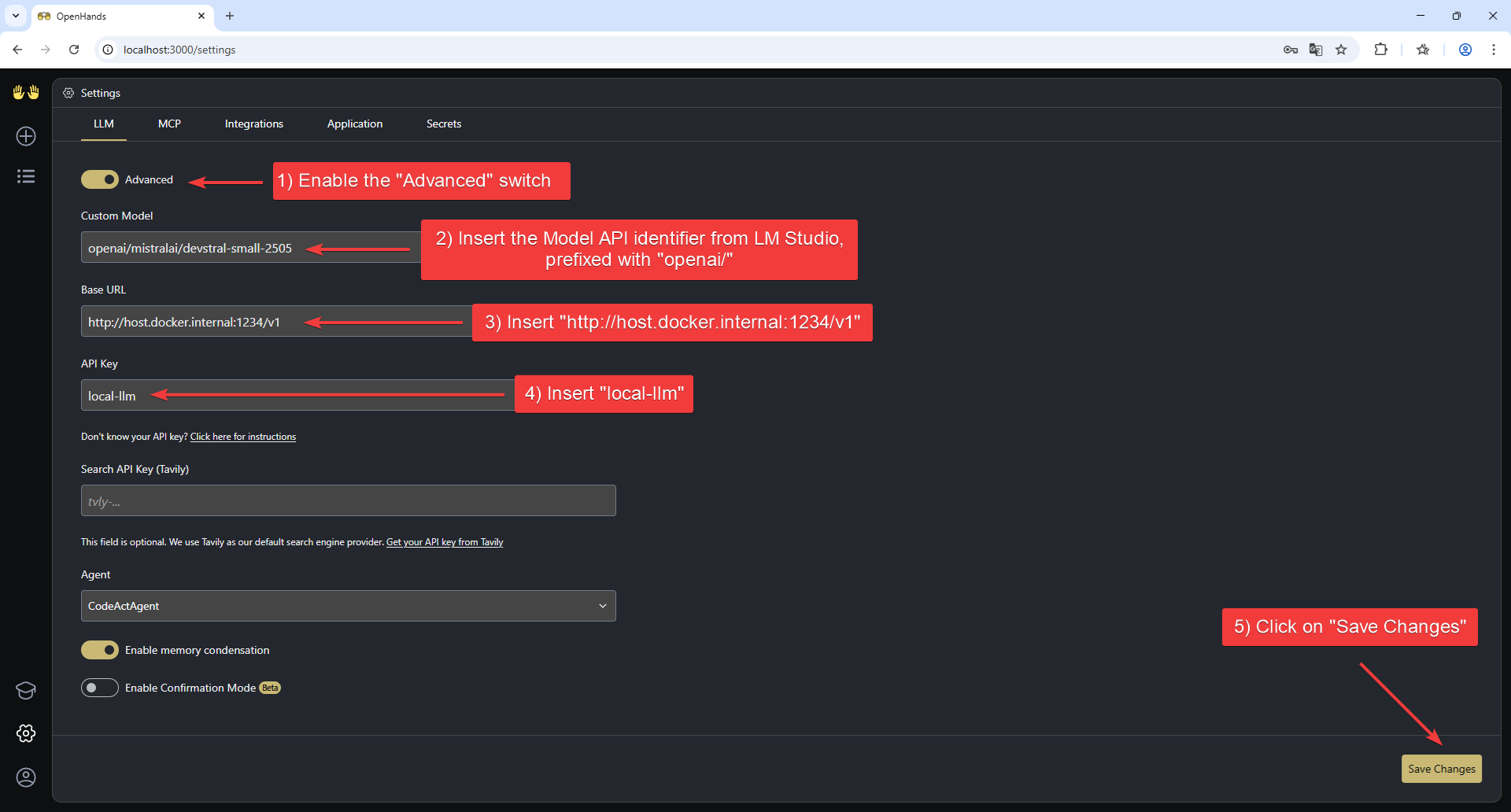
- Enable the “Advanced” switch at the top of the page to show all the available settings.
-
Set the following values:
- Custom Model:
openai/mistralai/devstral-small-2505(the Model API identifier from LM Studio, prefixed with “openai/”) - Base URL:
http://host.docker.internal:1234/v1 - API Key:
local-llm
- Custom Model:
- Click “Save Settings” to save the configuration.
Advanced: Alternative LLM Backends
This section describes how to run local LLMs with OpenHands using alternative backends like Ollama, SGLang, or vLLM — without relying on LM Studio.Create an OpenAI-Compatible Endpoint with Ollama
- Install Ollama following the official documentation.
- Example launch command for Devstral Small 2505:
Create an OpenAI-Compatible Endpoint with vLLM or SGLang
First, download the model checkpoints. For Devstral Small 2505:Serving the model using SGLang
- Install SGLang following the official documentation.
- Example launch command for Devstral Small 2505 (with at least 2 GPUs):
Serving the model using vLLM
- Install vLLM following the official documentation.
- Example launch command for Devstral Small 2505 (with at least 2 GPUs):
- Install the Arctic Inference library that automatically patches vLLM:
- Run the launch command with speculative decoding enabled:
Run OpenHands (Alternative Backends)
Using Docker
Run OpenHands using the official docker run command.Using Development Mode
Use the instructions in Development.md to build OpenHands. Start OpenHands usingmake run.
Configure OpenHands (Alternative Backends)
Once OpenHands is running, open the Settings page in the UI and go to theLLM tab.
- Click “see advanced settings” to access the full configuration panel.
- Enable the Advanced toggle at the top of the page.
- Set the following parameters, if you followed the examples above:
- Custom Model:
openai/<served-model-name>e.g.openai/devstralif you’re using Ollama, oropenai/Devstral-Small-2505for SGLang or vLLM. - Base URL:
http://host.docker.internal:<port>/v1Use port11434for Ollama, or8000for SGLang and vLLM. - API Key:
- For Ollama: any placeholder value (e.g.
dummy,local-llm) - For SGLang or vLLM: use the same key provided when starting the server (e.g.
mykey)
- For Ollama: any placeholder value (e.g.
- Custom Model: